Квадрат числа N
В данном примере будет показано, как с помощью GPU можно посчитать квадрат числа N. Также, как и в предыдущих примерах особое внимание будет уделено специфике CUDA C при написании программ.
Программа будет выполняться на GPU, а вызываться из CPU, то есть снова используется спецификатор __global__. В __global__ вычисление будет считаться на одном потоке с i количеством блоков. Тут же будет считаться арифметические операции. Сравнение i<N это есть сравнение количества потоков и количества элементов матрицы и до тех пор, пока утверждение будет истинно, матрица будет увеличиваться в квадрате. В главной функции мы создаем матрицы на хосте (int ha[N], hb[N]) и объявляем указатели на матрицы GPU (int *da, *db). Тут же происходит выделение памяти и инициализация входных значений. Далее входные данные отправляются на GPU, чтобы произвести расчет add в N потоках по каждому элементу. Освобождаем память и выводим значения на экран.
Ниже представлен код программы:
#include <stdio.h> #define N 24 __global__ void add(int *a, int *b) { int i = blockIdx.x; if (i<N) { b[i] = a[i]*a[i]; } } int main() { int ha[N], hb[N]; int *da, *db; cudaMalloc((void **)&da, N*sizeof(int)); cudaMalloc((void **)&db, N*sizeof(int)); for (int i = 0; i<N; ++i) { ha[i] = i; } cudaMemcpy(da, ha, N*sizeof(int), cudaMemcpyHostToDevice); add<<<N, 1>>>(da, db); cudaMemcpy(hb, db, N*sizeof(int), cudaMemcpyDeviceToHost); for (int i = 0; i<N; ++i) { printf("%d\n", hb[i]); } cudaFree(da); cudaFree(db); return 0; }
Результат выполнения программы:

CUDA SAXPY
SAXPY означает «Single-Precision A · X Plus Y». Это функция в стандартной библиотеке подпрограмм базовой линейной алгебры (BLAS). SAXPY — это комбинация скалярного умножения и сложения векторов, то есть: в качестве входных данных принимается два 32-разрядных вектора X и Y с N элементами каждый и скалярное значение A. Далее происходит умножение каждого элемента X [i] на A, а получение результата приходит к Y [i].
Также в примере будет продемонстрирована эффективная пропускная способность и как ее считать.
Простая реализация C выглядит так.
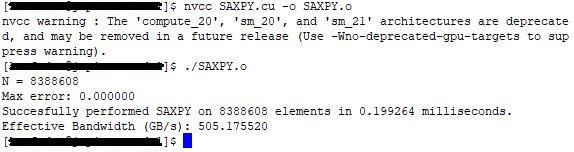
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <stdio.h> #include <math.h> #include <stdlib.h> __global__ void saxpy(int n, float a, float *x, float *y) { int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < n) { y[i] = a*x[i] + y[i]; } } int main() { int N = 1<<23; int size = N*sizeof(float); printf("N = %d\n",N); // Создание обработчиков событий CUDA cudaEvent_t start, stop; cudaEventCreate(&start); cudaEventCreate(&stop); float *x, *y; // Вектора на хосте float *d_x, *d_y; // Вектора на устройстве // Выделение памяти на хосте x = (float *)malloc(size); y = (float *)malloc(size); // Выделение памяти на устройстве cudaMalloc(&d_x, size); cudaMalloc(&d_y, size); for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; } cudaMemcpy(d_x, x, size, cudaMemcpyHostToDevice); cudaMemcpy(d_y, y, size, cudaMemcpyHostToDevice); // Выполнение SAXPY на 1 миллионе элементов cudaEventRecord(start); saxpy<<<(N+255)/256, 256>>>(N, 2.0, d_x, d_y); cudaEventRecord(stop); cudaMemcpy(y, d_y, size, cudaMemcpyDeviceToHost); cudaEventSynchronize(stop); float milliseconds = 0; cudaEventElapsedTime(&milliseconds, start, stop); float maxError = 0.0f; for (int i = 0; i < N; i++) { maxError = max(maxError, abs(y[i]-4.0f)); } printf("Max error: %f\n", maxError); printf("Succesfully performed SAXPY on %d elements in %f milliseconds.\n", N, milliseconds); //Время выполнения программы на N элементах printf("Effective Bandwidth (GB/s): %f\n", N*4*3/milliseconds/1e6); //Эффективная пропускная способность Гб/сек }
Результат выполнения программы: