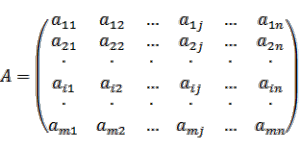


Увеличение значение у элементов в матрице на единицу
Следующая программа будет увеличивать значение элемента в матрице на единицу. Объяснение этой программы и последующих будет построено несколько иным образом, так как останавливаться на каждой строчке и объяснять один и тот же механизм будет достаточно скучным чтением.
Поэтому ниже будет приведен листинг всего кода с комментариями по новым вещам, что ранее в программах не было, а после каждый момент будет подробно разобран. Итак, листинг:
#include <stdio.h> __global__ void incKernel ( float * data ) { int idx = blockIdx.x * blockDim.x + threadIdx.x; data [idx] = data [idx] + 1.0f; } int main ( int argc, char * argv [] ) { int n = 16 * 1024 * 1024; int numBytes = n * sizeof ( float ); // выделение памяти на хосте float * a = new float [n]; for ( int i = 0; i < n; i++ ) a [i] = 0.0f; // выделение памяти на девайсе float * dev = NULL; cudaMalloc ( (void**)&dev, numBytes ); // Установка конфигурации запуска ядра dim3 threads = dim3(512, 1); dim3 blocks = dim3(n / threads.x, 1); // создание обработчиков событий cuda cudaEvent_t start, stop; float gpuTime = 0.0f; cudaEventCreate ( &start ); cudaEventCreate ( &stop ); // асинхронно выдаем работу на GPU (все в поток 0) cudaEventRecord ( start, 0 ); cudaMemcpy ( dev, a, numBytes, cudaMemcpyHostToDevice ); incKernel<<<blocks, threads>>>(dev); cudaMemcpy ( a, dev, numBytes, cudaMemcpyDeviceToHost ); cudaEventRecord ( stop, 0 ); cudaEventSynchronize ( stop ); cudaEventElapsedTime ( &gpuTime, start, stop ); // Печатаем время работы на CPU и GPU printf("time spent executing by the GPU: %.2f millseconds\n", gpuTime ); // проверка аутпута на корректность printf("--------------------------------------------------------------\n"); for ( int i = 0; i < n; i++ ) if ( a [i] != 1.0f ) { printf ( "Error in pos %d, %f\n", i, a [i] ); break; } // освобождение ресурсов cudaEventDestroy ( start ); cudaEventDestroy ( stop ); cudaFree( dev ); delete a; return 0; }
В примере продемонстрирован обработчик событий, который не был ранее описан. Итак, обработчик событий CUDA cudaEvent_t start, stop задает начало и конец события. С помощью переменной float gpuTime = 0.0f будет производиться расчет времени выполнения программы в миллисекундах. Запись события производится с помощью специального объявления cudaEventRecord ( start/stop, 0 ). Вычисление времени производится с помощью cudaEventElapsedTime. Это время, которое потребовалось для вычисления только на стороне GPU. В последующих примерах работа с записью времени подробно описываться не будет, за исключением того, что не было описано здесь.
В данном примере ядро устроено следующим образом: каждому треду соответствует один тред, блоки и grid одномерны. Ядро (она же функция incKernel) на вход получает только указатель на массив с данными в глобальной памяти. Задача ядра — по threadIdx и blockIdx определить какой именно элемент соответствует данному треду и увеличить именно его.
Так как и блоки и grid одномерны, то номер треда будет определятся как произведение номера блока на количество тредов в блоке, плюс номер треда внутри блока, т.е. blockIdx.x * blockDim.x + threadIdx.x.
Функция main несколько сложнее — она должна подготовить массив с данными в памяти CPU, после чего при помощи cudaMalloc выделяется память под копию массива с данными в глобальной памяти (DRAM GPU). Далее данные копируются функцией cudaMemcpy из памяти CPU к глобальную память GPU.
По завершению копирования данных в глобальную память запускается ядро для обработки данных и после его вызова копируются результаты вычислений обратно из глобальной памяти GPU в память CPU.
Результатом выполнения будет замер затраченного на копирование и вычисления времени программы, а также проверка на корректность получаемого результата:
Перемножение двух матриц
Следующий пример будет чуть сложнее, но не менее интереснее — перемножение двух квадратных матриц размерности N*N.
Допустим у нас есть две квадратные матрицы A и B размера N*N (будем считать, что N кратно 16). Простейший вариант использует по одному треду на каждый элемент получающейся матрицы C, при этом тред извлекает все необходимые элементы из глобальной памяти и производит требуемые вычисления.
Элемент ci,j произведения двух матриц A и B вычисляется следующим фрагментом псевдокода:
c [i][j] считать равным нулю;
Для каждого k-го элемента от 0 до N-1 считать:
c [i][j] += a [i][k] * b [k][j]
Таким образом для вычисления одного элемента произведения матриц нужно выполнить 2*N арифметических операций и 2*N чтений из глобальной памяти. Очевидно, что в основным лимитирующим фактором является скорость доступа к глобальной памяти, которая весьма низка. Опустим этот момент (его мы разберем в следующем примере), так как пример демонстрирует перемножение двух квадратных матриц, а не оптимизирует скорость доступа. Итак, листинг:
#include <stdio.h> #define BLOCK_SIZE 16 // submatrix size #define N 1024 // matrix size is N*N __global__ void matMult ( float * a, float * b, int n, float * c ) { int bx = blockIdx.x; // block index int by = blockIdx.y; int tx = threadIdx.x; // thread index int ty = threadIdx.y; float sum = 0.0f; // computed subelement int ia = n * BLOCK_SIZE * by + n * ty; // a [i][0] int ib = BLOCK_SIZE * bx + tx; // Multiply the two matrices together; for ( int k = 0; k < n; k++ ) sum += a [ia + k] * b [ib + k*n]; // Write the block sub-matrix to global memory; // each thread writes one element int ic = n * BLOCK_SIZE * by + BLOCK_SIZE * bx; c [ic + n * ty + tx] = sum; } int main ( int argc, char * argv [] ) { int numBytes = N * N * sizeof ( float ); // выделение памяти на хосте float * a = new float [N*N]; float * b = new float [N*N]; float * c = new float [N*N]; for ( int i = 0; i < N; i++ ) for ( int j = 0; j < N; j++ ) { int k = N*i + j; a [k] = 0.0f; b [k] = 1.0f; } // выделение памяти на девайсе float * adev = NULL; float * bdev = NULL; float * cdev = NULL; cudaMalloc ( (void**)&adev, numBytes ); cudaMalloc ( (void**)&bdev, numBytes ); cudaMalloc ( (void**)&cdev, numBytes ); // Установка конфигурации запуска ядра dim3 threads ( BLOCK_SIZE, BLOCK_SIZE ); dim3 blocks ( N / threads.x, N / threads.y); // Создание обработчика событий CUDA cudaEvent_t start, stop; float gpuTime = 0.0f; cudaEventCreate ( &start ); cudaEventCreate ( &stop ); // асинхронно выдаваем работу на GPU (все в поток 0) cudaEventRecord ( start, 0 ); cudaMemcpy ( adev, a, numBytes, cudaMemcpyHostToDevice ); cudaMemcpy ( bdev, b, numBytes, cudaMemcpyHostToDevice ); matMult<<<blocks, threads>>> ( adev, bdev, N, cdev ); cudaMemcpy ( c, cdev, numBytes, cudaMemcpyDeviceToHost ); cudaEventRecord ( stop, 0 ); cudaEventSynchronize ( stop ); cudaEventElapsedTime ( &gpuTime, start, stop ); // Печатаем время работы на GPU и CPU printf("time spent executing by the GPU: %.2f millseconds\n", gpuTime ); // Освобождение ресурсов cudaEventDestroy ( start ); cudaEventDestroy ( stop ); cudaFree ( adev ); cudaFree ( bdev ); cudaFree ( cdev ); delete a; delete b; delete c; return 0; }
Естественно, саму матрицу вы можете задать произвольно, в данном примере была указана лишь размерность без каких-либо значений элементов. Данный пример демонстрирует производительность перемножения двух матриц размерностей N*N:
Перемножение двух матриц с использованием shared-памяти
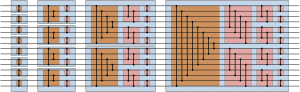
А теперь непосредственно разберем быстродействие программы за счет использования shared-памяти. Для этого нужно разбить результирующую матрицы на подматрицы 16*16, вычислением каждой такой подматрицы будет заниматься один блок. Обратите внимание, что для вычисления такой подматрицы нужны только небольшие «бэнды» матриц A и B .
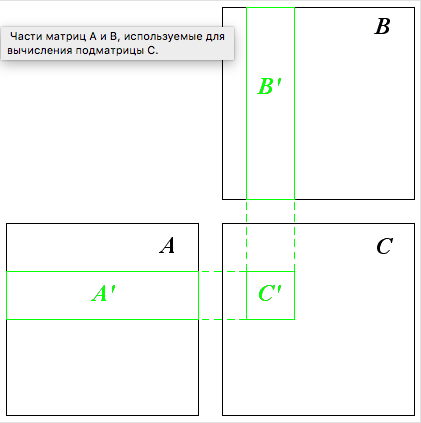
К сожалению нет возможности копировать «бэнды» в shared-память из-за довольно небольшого объема shared-памяти. Поэтому можно поступить другим образом — разбить бэнды на матрицы 16*16 и вычисление подматрицы произведения матриц будем проводить в N/16 шагов.
Поскольку используется разбиение бэндов на квадратные подматрицы, то псевдокод расчета элемент ci,j изменится:
c [i][j] равен нулю;
Для каждого шага от 0 до N/16 считать:
По каждому k-му элементу от 0..16 считать:
c [i][j] += a [i][k+step*16] * b [k+step*16][j]
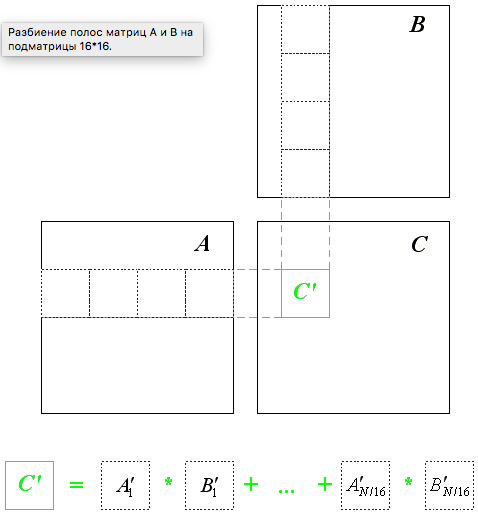
Следует обратить внимание, что для каждого значения step значения из матриц A и B берутся из двух подматриц размером 16*16. Фактически полосы с рис. 4 просто поделены на квадратные подматрицы и каждому значению step соответствует по одной такой подматрице A и одной подматрице B.
На каждом шаге будем загружать в shared-память по одной 16*16 подматрице A и одной 16*16 подматрице B. Далее будем вычислять соответствующую им сумму для элементов произведения, потом загружаем следующие 16*16-подматрицы и т.д.
При этом на каждом шаге один тред загружает ровно по одному элементу из каждой из матриц A и B и вычисляет соответствующую им сумму членов. По окончании всех вычислений производится запись элемента в итоговую матрицу.
Следует обратить внимание, что после загрузки элементов из A и B нужно выполнить синхронизацию тредов при помощи вызова __synchronize для того, чтобы к моменту начала расчетов все нужные элементы (загружаемые остальными тредами блока) были бы уже загружены. Точно также по окончании обработки загруженных подматриц и перед загрузкой следующих также нужна синхронизация.
Ниже приводится соответствующий исходный код:
#include <stdio.h> #define BLOCK_SIZE 16 // submatrix size #define N 1024 // matrix size is N*N __global__ void matMult ( float * a, float * b, int n, float * c ) { int bx = blockIdx.x; // block index int by = blockIdx.y; int tx = threadIdx.x; // thread index int ty = threadIdx.y; // Index of the first sub-matrix of A processed by the block int aBegin = n * BLOCK_SIZE * by; int aEnd = aBegin + n - 1; // Step size used to iterate through the sub-matrices of A int aStep = BLOCK_SIZE; // Index of the first sub-matrix of B processed by the block int bBegin = BLOCK_SIZE * bx; // Step size used to iterate through the sub-matrices of B int bStep = BLOCK_SIZE * n; float sum = 0.0f; // computed subelement for ( int ia = aBegin, ib = bBegin; ia <= aEnd; ia += aStep, ib += bStep ) { // Shared memory for the sub-matrix of A __shared__ float as [BLOCK_SIZE][BLOCK_SIZE]; // Shared memory for the sub-matrix of B __shared__ float bs [BLOCK_SIZE][BLOCK_SIZE]; // Load the matrices from global memory to shared memory; as [ty][tx] = a [ia + n * ty + tx]; bs [ty][tx] = b [ib + n * ty + tx]; __syncthreads(); // Synchronize to make sure the matrices are loaded // Multiply the two matrices together; for ( int k = 0; k < BLOCK_SIZE; k++ ) sum += as [ty][k] * bs [k][tx]; // Synchronize to make sure that the preceding // computation is done before loading two new // sub-matrices of A and B in the next iteration __syncthreads(); } // Write the block sub-matrix to global memory; // each thread writes one element int ic = n * BLOCK_SIZE * by + BLOCK_SIZE * bx; c [ic + n * ty + tx] = sum; } int main ( int argc, char * argv [] ) { int numBytes = N * N * sizeof ( float ); // allocate host memory float * a = new float [N*N]; float * b = new float [N*N]; float * c = new float [N*N]; for ( int i = 0; i < N; i++ ) for ( int j = 0; j < N; j++ ) { a [i] = 0.0f; b [i] = 1.0f; } // allocate device memory float * adev = NULL; float * bdev = NULL; float * cdev = NULL; cudaMalloc ( (void**)&adev, numBytes ); cudaMalloc ( (void**)&bdev, numBytes ); cudaMalloc ( (void**)&cdev, numBytes ); // set kernel launch configuration dim3 threads ( BLOCK_SIZE, BLOCK_SIZE ); dim3 blocks ( N / threads.x, N / threads.y); // create cuda event handles cudaEvent_t start, stop; float gpuTime = 0.0f; cudaEventCreate ( &start ); cudaEventCreate ( &stop ); // asynchronously issue work to the GPU (all to stream 0) cudaEventRecord ( start, 0 ); cudaMemcpy ( adev, a, numBytes, cudaMemcpyHostToDevice ); cudaMemcpy ( bdev, b, numBytes, cudaMemcpyHostToDevice ); matMult<<<blocks, threads>>> ( adev, bdev, N, cdev ); cudaMemcpy ( c, cdev, numBytes, cudaMemcpyDeviceToHost ); cudaEventRecord ( stop, 0 ); cudaEventSynchronize ( stop ); cudaEventElapsedTime ( &gpuTime, start, stop ); // print the cpu and gpu times printf("time spent executing by the GPU: %.2f millseconds\n", gpuTime ); // release resources cudaEventDestroy ( start ); cudaEventDestroy ( stop ); cudaFree ( adev ); cudaFree ( bdev ); cudaFree ( cdev ); delete a; delete b; delete c; return 0; }
Теперь для вычисления одного элемента произведения матриц нам нужно всего 2*N/16 чтений из глобальной памяти. И по результатам сразу видно за счет использования shared-памяти нам удалось поднять быстродействие более чем на порядок – 3.66 милисекунд: