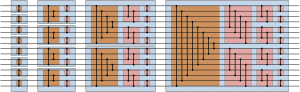
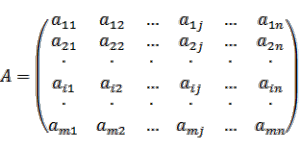На данном занятии читатель познакомится с основами практики программирования на CUDA C – будет подробно описано написание кода, его суть и исполнение. В качестве примеров будут разобраны самые популярные и полезные задачи, среди которых можно выделить:
арифметические операции (сложение, умножение) с числами и матрицами, добавление массива, генерация псевдослучайных чисел, увеличение значений в матрице, алгоритмы сортировки и т.д. В примерах будут разобраны такие моменты, как комбинация тредов и блоков, применение shared-памяти в решении задачи, использование SAXPY («Single-Precision A · X Plus Y»).
Сложение двух чисел
#include <stdio.h> __global__ void add( int *a, int *b, int *c ) { *c = *a + *b; } int main( void ) { int a, b, c; // host копии a, b, c int *dev_a, *dev_b, *dev_c; // device копии of a, b, c int size = sizeof( int ); //выделяем память для device копий для a, b, c cudaMalloc( (void**)&dev_a, size ); cudaMalloc( (void**)&dev_b, size ); cudaMalloc( (void**)&dev_c, size ); a = 5; b = 10; // копируем ввод на device cudaMemcpy( dev_a, &a, size, cudaMemcpyHostToDevice ); cudaMemcpy( dev_b, &b, size, cudaMemcpyHostToDevice ); // запускаем add() kernel на GPU, передавая параметры add<<< 1, 1 >>>( dev_a, dev_b, dev_c ); // copy device result back to host copy of c cudaMemcpy( &c, dev_c, size, cudaMemcpyDeviceToHost ); cudaFree( dev_a ); cudaFree( dev_b ); cudaFree( dev_c ); return 0; }
Также, как и в предыдущих примерах прописываем спецификатор __global__, внутри которого 3 аргумента — 2 числа и результат их сложения. В теле этой функции прописываем саму арифметическую операцию *c = *a + *b.
В главной функции переменные разделяются на две части: на хосте и на девайсе (названия переменных помечены соответственно), кроме этого указывается переменная, отвечающая за размер данных — int size. Далее выделяем память на GPU с помощью команды cudaMalloc, в аргументах прописаны указатели памяти на указатели типа void поадресно (dev_a, dev_b, dev_c) и выделяемый размер памяти для каждой переменной. Прописываем значения переменных a и b (например 5 и 10). Копируем значения на GPU и запускаем ядро GPU с помощью команды add<<< 1, 1 >>>( dev_a, dev_b, dev_c );. Копируем результат переменной c обратно на CPU и освобождаем память.
Перейдем к примерам посложнее, когда нужно менять значение блоков, тредов поочередно и одновременно. Подробное описание в них будет опущено, за исключением комментариев в самом коде.
Сложение двух чисел с использованием N-блоков по одному треду
__global__ void add( int *a, int *b, int *c ) { c[blockIdx.x] = a[blockIdx.x] + b[blockIdx.x]; } #define N 512 int main( void ) { int *a, *b, *c; // host копии a, b, c int *dev_a, *dev_b, *dev_c; // device копии a, b, c int size = N * sizeof( int ); //выделяем память для device копий a, b, c cudaMalloc( (void**)&dev_a, size ); cudaMalloc( (void**)&dev_b, size ); cudaMalloc( (void**)&dev_c, size ); a = (int*)malloc( size ); b = (int*)malloc( size ); c = (int*)malloc( size ); random_ints( a, N ); random_ints( b, N ); // копируем ввод на device cudaMemcpy( dev_a, a, size, cudaMemcpyHostToDevice ); cudaMemcpy( dev_b, b, size, cudaMemcpyHostToDevice ); // launch add() kernel with N parallel blocks add<<< N, 1 >>>( dev_a, dev_b, dev_c ); // копируем результат работы device обратно на host - копию c cudaMemcpy( c, dev_c, size, cudaMemcpyDeviceToHost ); free( a ); free( b ); free( c ); cudaFree( dev_a ); cudaFree( dev_b ); cudaFree( dev_c ); return 0; }
Сложение двух чисел с одним блоком и N-тредов
__global__ void add( int *a, int *b, int *c ) { c[ threadIdx.x ] = a[ threadIdx.x ] + b[ threadIdx.x ]; // blockIdx.x blockIdx.x blockIdx.x } #define N 512 int main( void ) { int *a, *b, *c; //host копии a, b, c int *dev_a, *dev_b, *dev_c; //device копии of a, b, c int size = N * sizeof( int ); //выделяем память для копий a, b, c cudaMalloc( (void**)&dev_a, size ); cudaMalloc( (void**)&dev_b, size ); cudaMalloc( (void**)&dev_c, size ); a = (int*)malloc( size ); b = (int*)malloc( size ); c = (int*)malloc( size ); random_ints( a, N ); random_ints( b, N ); // копируем ввод device cudaMemcpy( dev_a, a, size, cudaMemcpyHostToDevice ); cudaMemcpy( dev_b, b, size, cudaMemcpyHostToDevice ); // запускаем на выполнение add() kernel с N тредами в блоке add<<< 1, N >>>( dev_a, dev_b, dev_c ); // N, 1 // копируем результат работы device обратно на host (копия c) cudaMemcpy( c, dev_c, size, cudaMemcpyDeviceToHost ); free( a ); free( b ); free( c ); cudaFree( dev_a ); cudaFree( dev_b ); cudaFree( dev_c ); return 0; }
Сложение двух чисел с использованием N-блоков и N-тредов
__global__ void add( int *a, int *b, int *c ) { int index = threadIdx.x + blockIdx.x * blockDim.x; c[index] = a[index] + b[index]; } #define N (2048*2048) #define THREADS_PER_BLOCK 512 int main( void ) { int *a, *b, *c; // host копии a, b, c int *dev_a, *dev_b, *dev_c; // device копии of a, b, c int size = N * sizeof( int ); //выделяем память на device для of a, b, c cudaMalloc( (void**)&dev_a, size ); cudaMalloc( (void**)&dev_b, size ); cudaMalloc( (void**)&dev_c, size ); a = (int*)malloc( size ); b = (int*)malloc( size ); c = (int*)malloc( size ); random_ints( a, N ); random_ints( b, N ); //копируем ввод на device cudaMemcpy( dev_a, a, size, cudaMemcpyHostToDevice ); cudaMemcpy( dev_b, b, size, cudaMemcpyHostToDevice ); //запускаем на выполнение add() kernel с блоками и тредами add<<< N/THREADS_PER_BLOCK, THREADS_PER_BLOCK >>>( dev_a, dev_b, dev_c ); // копируем результат работы device на host ( копия c ) cudaMemcpy( c, dev_c, size, cudaMemcpyDeviceToHost ); free( a ); free( b ); free( c ); cudaFree( dev_a ); cudaFree( dev_b ); cudaFree( dev_c ); return 0; }