Занятие 6. Программирование на CUDA C. Часть 2.
Скалярное произведение с использованием shared-памяти
Треды на первый взгляд кажутся избыточными. Параллельные треды, в отличие параллельных блоков, имеют механизмы для, так называемых, коммуникации и синхронизации. Давайте рассмотрим этот вопрос.
Возьмем в качестве примера на этот раз не сложение, а скалярное произведение.
Треды в одном блоке могут иметь общую память shared memory. Эта память декларируется в коде ключевым словом __shared__. Эта память не видна в другом блоке.
__syncthreads().
Ниже представлен код с синхронизацией и использованием shared memory:
//__global__ void dot( int *a, int *b, int *c ) { // Каждый тред вычисляет одно слагаемое скалярного произведения // int temp = a[threadIdx.x] * b[threadIdx.x]; //Не может вычислить сумму //Каждая копия ‘temp’ приватна для своего треда //} __global__ void dot( int *a, int *b, int *c ) { __shared__ int temp[N]; temp[threadIdx.x] = a[threadIdx.x] * b[threadIdx.x]; __syncthreads(); if( 0 == threadIdx.x ) { int sum = 0; for( int i = 0; i < N; i++ ) sum += temp[i]; *c = sum; } } #define N 512 int main( void ) { int *a, *b, *c; int *dev_a, *dev_b, *dev_c; int size = N * sizeof( int ); cudaMalloc( (void**)&dev_a, size ); cudaMalloc( (void**)&dev_b, size ); cudaMalloc( (void**)&dev_c, sizeof( int ) ); a = (int *)malloc( size ); b = (int *)malloc( size ); c = (int *)malloc( sizeof( int ) ); random_ints( a, N ); random_ints( b, N ); // копируем ввод на device cudaMemcpy( dev_a, a, size, cudaMemcpyHostToDevice ); cudaMemcpy( dev_b, b, size, cudaMemcpyHostToDevice ); //запускаем на выполнение dot() kernel с 1 блоком и N тредами dot<<< 1, N >>>( dev_a, dev_b, dev_c ); //копируем результат работы device на host копией c cudaMemcpy( c, dev_c, sizeof( int ) , cudaMemcpyDeviceToHost ); free( a ); free( b ); free( c ); cudaFree( dev_a ); cudaFree( dev_b ); cudaFree( dev_c ); return 0; }
Сложение двух векторов
При создании любого проекта на CUDA в Visual Studio происходит генерация кода, который демонстрирует сложение двух векторов. Это очень полезный и показательный пример работы с CUDA. Он будет представлен в следующем разделе, а пока давайте создадим собственную программу с нуля.
Необходимые библиотеки:
является библиотекой от расширения CUDA C. Она нужна для того, чтобы можно было получать встроенные модули (например, типы данных) и была возможность использования API CUDA во время выполнения компиляции с хоста. Если вы будете использовать компилятор CUDA nvcc, то прописывать данную библиотеку необязательно, так как этот заголовок подключается автоматически (помимо cuda_runtime.h, это также касается cuda_runtime_api.h и cuda.h).
Следующим шагом будет добавление спецификатора __global__, его функция с аргументами. Среди аргументов обозначим 2 вектора const float * a и const float * b, результат float * result и счетчик int n:
__global__ void vecAdd_kernel(
const float * a, const float * b, float * result, int n)
Далее введем новую переменную целочисленного типа i со значением blockIdx.x * blockDim.x + threadIdx.x, обозначающую размерность блоков и грида. В данном случае одномерная модель блоков и грида. В таком случае номер треда будет определяться как номер блока, умноженный на количество тредов в блоке, плюс номер треда внутри блока.
Дальше идет сравнение переменной i со счетчиком и запись результата сложения.
n)
После чего в главной функции программы задаем нашему счетчику значение 100, также в главной функции выделяем память под каждую переменную, включая полученный результат.
i++, а в теле цикла будет сравниваться a и b с i при этом i будет увеличиваться на единицу (i++).
Далее происходит копирование данных из памяти CPU в память GPU с помощью функции cudaMemcpy. В аргументах указываем переменную с GPU и CPU, выделяемый размер и команду cudaMemcpyHostToDevice:
Далее обозначаем размер блоков const int block_size = 256 и считаем количество блоков, которое потом будет вызываться в ядре:
int num_blocks = (n + block_size - 1) / block_size
Вызываем ядро, записываем результат и снова через cudaMemcpy передаем его уже с GPU на CPU (cudaMemcpyDeviceToHost):
cudaMemcpy(result, result_gpu,
Снова создаем цикл, который в дальнейшем напечатает результаты сложения векторов, которых будет равно количеству x:
x++)
Уничтожаем (освобождаем) массивы a, b, result на CPU и на GPU с помощью команды cudaFree:
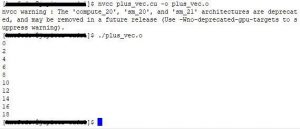
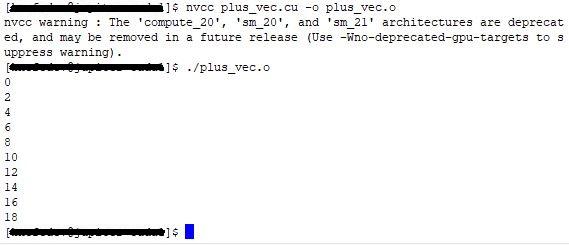
Таким образом, была реализована программа, которая складывает 2 вектора и показывает на экране результат их сложения. Листинг всей программы приведен ниже:
#include <iostream>
#include <cuda_runtime.h>
using namespace std;
__global__ void vecAdd_kernel(
const float * a, const float * b, float * result, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n)
result[i] = a[i] + b[i];
}
int main() {
int n = 100;
float * a = new float[n], * a_gpu;
cudaMalloc((void**)&a_gpu, n * sizeof(float));
float * b = new float[n], * b_gpu;
cudaMalloc((void**)&b_gpu, n * sizeof(float));
float * result = new float[n], * result_gpu;
cudaMalloc((void**)&result_gpu, n * sizeof(float));
for (int i = 0; i < n; i++)
a[i] = b[i] = i;
cudaMemcpy(a_gpu, a, n * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(b_gpu, b, n * sizeof(float), cudaMemcpyHostToDevice);
const int block_size = 256;
int num_blocks = (n + block_size - 1) / block_size;
vecAdd_kernel <<< num_blocks, block_size >>> (a_gpu, b_gpu, result_gpu, n);
cudaMemcpy(result, result_gpu,
n * sizeof(float), cudaMemcpyDeviceToHost);
for (int x = 0; x < 10; x++)
cout<<result[x]<<endl;
delete [] a;
delete [] b;
delete [] result;
cudaFree(a_gpu);
cudaFree(b_gpu);
cudaFree(result_gpu);
return 0;
}
А результат выполнения программы вы можете увидеть на рисунке: