
I Архитектуры современных процессов, их особенности в рамках параллельности выполнение
Классификация архитектур вычислительных систем по Флинну. Какие существуют типы параллелизма? Организация памяти при параллельной обработки данных.
Классификация архитектур вычислительных систем по Флинну
Как известно, из классификаций архитектур вычислительных систем самой первой и наиболее известной является представленная в 1966 [1] году М.Флинном. Данная классификация основывается на понятии потока – последовательность команд, элементов или данных, обрабатываемая процессором. Флинн выделяет четыре класса архитектур на основе числа потоков команд и потоков данных: SISD,MISD,SIMD,MIMD.
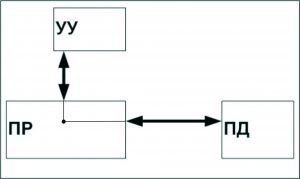
SISD (single instruction stream / single data stream) – одиночный поток команд и одиночный поток данных. К данному классу принадлежат классические последовательные машины, или их ещё называют, машины фон-неймановского типа. Данные машины имеют только один поток команд, обрабатывающиеся последовательно друг за другом и каждая команда инициирует одну операцию с одним потоком данных. Все однопоточные программы используют вычислительную систему в этом режиме.
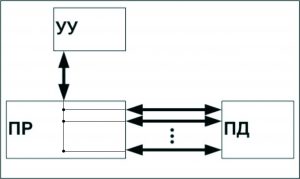
SIMD (single instruction stream / multiple data stream) – одиночный поток команд и множественный поток данных. Подобного рода архитектуры сохраняют один поток команд, включающий, векторные команды, в отличие от предыдущего класса. Это позволяет выполнять одну арифметическую операцию сразу над многими данными – элементами вектора. Примерами SIMD-машин являются системы CPP DAP, Gamma II и Quadrics Apemille. Другим подклассом SIMD-систем являются векторные компьютеры.
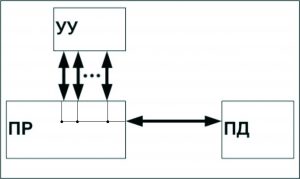
MISD (multiple instruction stream / single data stream) – множественный поток команд и одиночный поток данных. Данный класс предполагает, что в архитектуре имеется множество процессоров, которые обрабатывают один и тот же поток данных. Однако до сих пор нет реального примера существования вычислительной системы, построенной на данном принципе. Как аналог работы такой системы, можно представить работу банка. С любого терминала можно подать команду и что-то сделать с имеющимся банком данных. Так как база данных одна, а команд много, то это и будет множественный поток команд и одиночный поток данных.
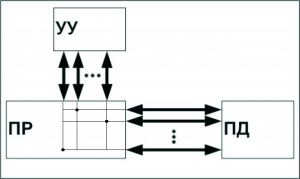
MIMD (multiple instruction stream / multiple data stream) – множественный поток команд и множественный поток данных. В данном классе, обрабатывается несколько данных, для которых выполняется несколько команд. К данному классу можно отнести многоядерные системы, а также все суперскалярные процессоры в общем виде.
В книге К.Ванга и Ф.Бриггса [2] сделаны некоторые дополнения к классификации Флина. Оставляя четыре ранее введенных базовых класса (SISD, SIMD, MISD, MIMD), авторы внесли следующие изменения.
Класс SISD разбивается на два подкласса:
- архитектуры с единственным функциональным устройством, например, PDP-11;
- архитектуры, имеющие в своем составе несколько функциональных устройств — CDC 6600, CRAY-1, FPS AP-120B, CDC Cyber 205, FACOM VP-200.
В класс SIMD также вводится два подкласса:
- архитектуры с пословно-последовательной обработкой информации — ILLIAC IV, PEPE, BSP;
- архитектуры с разрядно-последовательной обработкой — STARAN, ICL DAP.
В классе MIMD авторы различают:
- вычислительные системы со слабой связью между процессорами, к которым они относят все системы с распределенной памятью, например, Cosmic Cube,
- и вычислительные системы с сильной связью (системы с общей памятью), куда попадают такие компьютеры, как C.mmp, BBN Butterfly, CRAY Y-MP, Denelcor HEP.
Типы параллелизма
В источнике [3] выделяют четыре типа параллелизма: параллелизм на уровне битов, команд, данных, а также задач.
Параллелизм на уровне битов
При реализации операций обеспечивается максимальное распараллеливание, так, например, при осуществление сложения битов числа все биты машинного слова одновременно складываются, а так же используются специальный механизм учета переносов [4]. Чтобы увеличить диапазон чисел, обрабатываемых одной командой, следует увеличить размер машинного слова. Так, выполнен переход от 8-ми до 16-ти и далее к 32 разрядному машинному слову. На данный момент процессоры имеют 64-разрядное машинное слово, некоторые команды могут работать с 128-разрядными данными (процессор Larrabee работает с данными размером 512 битов). При использование машинного слова с большей разрядностью быстрее обрабатываются большие числа. Чтобы обработать 32-битное число для 16-битной машины требуется как минимум 2 команды, а для 32-битной – только одна. Но это верно не для всех 64-битных процессоров, ведь в них реализованы не все операции над 64-битными числами. так же ограничено использование команд, которые в результате дают 128-битные числа и числа большей разрядности.
Для определения диапазона адресного пространства также используется машинное слово. Вычислительная система работает с диапазоном адресного пространства, так как оно используется для задания адреса. Для 32-битных вычислительных систем максимальный адрес -1, адресное пространство составляет 4 ГБ. Для 64-битного машинного слова адресное пространство составляет или 16 ГБ. В табл. 1 представлены названия единиц измерения памяти.
таблица 1
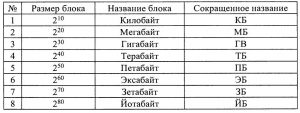
У первых вычислительных систем все числа занимали как минимум одно машинное слово, это приводило к неэффективному распределению памяти при задании небольших чисел. Для обеспечения эффективного распределения памяти в нынешних вычислительных системах, следует использовать данные разной длинны. Необходимость увеличения адресного пространства также является следствием усложнения решаемых задач. Для того, чтобы эффективно использовать 64-битные процессоры следует использовать операционную систему для работы с процессорами в 64-х битном режиме, а не использовать возможности этих процессоров работать в 32-битном режиме. Система Linux была первой операционной системой, которая полностью поддерживала работу процессора в этом режиме, далее появилась версия Microsoft Windows XP и Vista. На сегодняшний момент уже используются системы с оперативной памятью 16 ГБ, серверы с оперативной памятью 256ГБ, 8ГБ модули с оперативной памятью в серийном производстве.
Далее следует рассмотреть собственно параллелизм. Его можно реализовать как с помощью конвейера, так и суперескалярности, т.е. наличия нескольких независимых блоков для выполнения команд.
Параллелизм на уровне команд. Конвейер
Давно уже известна идея использования конвейера для увеличения производительности выполнения сложных операций. Происходит деление команды на независимые микрокоманды, время выполнения которых примерно одинаково. Количество микрокоманд равно числу блоков конвейера. Блоки конвейера последовательно обрабатывают очередную команду, выполняя ее микрокоманды. Полностью выполненной команда считается только после завершения обработки последним блоком конвейера.
Конвейерный принцип выполнения команд впервые был использован в машине ATLAS, 1962 г. [5], разработанной в Манчестерском университете. Выделяют 4 стадии выполнения команд: выборка команды, вычисление адреса операнда, выборка операнда и выполнение операции. Для Pentium в конвейер добавлен еще один блок записи результата. С помощью конвейеризации получилось уменьшить время выполнения команд с 6 до 1,6 микросекунд.
Время выполнения одной команды при ее последовательном выполнении от начала до конца примем за 1. Если конвейер состоит из m устройств (ступеней), то длина конвейер равна m. Если не брать в расчет накладные расходы, связанные с «перемещением» результатов выполнения предыдущих операций, то чтобы выполнить одну микрооперацию потребуется 1/m единиц времени. Далее выясним время выполнения программы, которая состоит из n последовательных команд без конвейера и с конвейером. Без конвейера потребуется n единиц времени (при том что время выполнения одной команды принято за 1).
Если использовать конвейер, то первая команда будет выполняться 1 единицу, а каждая очередная команда будет заканчиваться с интервалом 1/m единиц времени. Общее время выполнения такой программы равно 1+(n–1)/m.
Сравним полученные значения для n=100 команд и m=5 блоков конвейера. Без конвейера потребуется T1=100 (единиц времени), с конвейером T2=1+99/5=21 (единиц времени), т.е. почти в 5 раз быстрее. Конвейер позволяет увеличить производительность процессора, что интересно коэффициент ускорения почти прямо пропорционален длине конвейера. Именно поэтому длина конвейера для современных процессоров значительно больше 5. Конвейер Pentium 4 состоит из 35 блоков. Фактически увеличение числа блоков конвейера эквивалентно увеличению тактовой частоты, так как приводит к уменьшению времени выполнения одной команды.
Возникает тогда такой вопрос: можно ли бесконечно увеличивать число блоков конвейера? Нет, так как увеличение числа блоков способствует усложнению архитектуры процессора, увеличивает его тепловыделение. Время выполнения микрокоманды становится соизмеримым с накладными расходами, это уменьшает эффективность использования конвейера. Незнание свойств конвейера может поспособствовать потери производительности. Доказательством этого можно представить данный пример. Пусть в программе используется команда перехода. Для конвейера длиной 5 блоков адрес перехода определяется блоком 3, команду выполняет блок № 4 т.е. блоки второй половины конвейера. К моменту выполнения команды очередные 3 команды уже будут обработаны, несмотря на необходимость обрабатывать совсем другие команды. Такую ситуацию называют остановом конвейера. После того как определились адреса перехода, результаты обработки очередных команд должны быть аннулированы, а следующая команда, находящаяся по адресу перехода, начинает выполняться сначала. Если увеличить длину конвейера соответственно произойдет увеличение потерь, связанных с использованием команд перехода. Современные процессоры имеют блоки прогнозирования переходов, которые уменьшают потери, связанные с наличием команд перехода. Знание алгоритмов предсказания позволит снизить потери, связанные с командами перехода. Далее будут рассмотрены некоторые из них.
Команды сериализации
Конвейер считается одним из способов параллельного выполнения команды. Команды процессора имеют особые команды, которые чтобы начать выполнение ждут завершения всех начатых команд. При их выполнении другие команды не выполняются, данные команды имеют название команды сериализации. Приведем пример команды сериализации – команда cupid, использующаяся для определения особенностей процессора. Чтобы увеличить точность измерения времени, данную команду следует использовать перед началом и в конце замеров.
Предсказание переходов
Имеет свое начало с процессора типа Pentium. Дает возможность уменьшить потери производительности конвейера из-за наличия переходов.
Существует статистическое и динамическое предсказание. Для команд перехода, выполняющиеся в первый раз, используется статистическое предсказание. Для процессора типа Pentium – должна выполняться следующая команда, т.е. фактически нет предсказания.
Для процессоров имеющих более совершенный вид считалось, что ссылка вперед – перехода не будет, а ссылка назад – что переход будет. Это потому что, ссылка назад соответствует циклу, а пишутся циклы чтобы многократно выполнять один и тот же участок кода. Поэтому, статистическое предсказание верно, когда оператор условного перехода при первом его выполнении перехода не существует, т.е. имеет место естественный порядок выполнения команд. Исключением являются только циклы.
В процесс статистического предсказания команда заноситься в буфер предсказания перехода вместе с адресом, куда фактически выполняется переход. Так же устанавливается флаг в 1, если переход был.
Динамическое предсказание для Pentium. Данное предсказание применяется для команд перехода, выполняющихся повторно и которые уже имеют информацию. Каждая команда перехода имеет свой адрес (Адрес1), адрес, куда необходимо перейти (Адрес2) и битовые флаги (два флага). Если хотя бы один флаг из двух установлен в 1, то прогнозируется наличие перехода. Прогнозируется отсутствие перехода, при обоих флагах равны 0.
В дальнейшем в зависимости от того имеется переход или нет, значения флагов корректируются. Если переход есть и есть флаг, равный 0, то он устанавливается в 1. Если перехода нет и есть флаг равный 1, то он сбрасывается в 0. Данный алгоритм способствует минимизации числа ошибок, если очень маленькая вероятность наличия или отсутствия переходов. Если наличие переходов и их отсутствие равновероятны, то вероятность ошибок максимальна.
Динамическое предсказание для Pentium 2 и выше. Данное предсказание применяется для команд перехода, выполняющихся повторно и которые уже имеют информацию. Каждая команда перехода имеет свой адрес (Адрес1), адрес, куда необходимо перейти (Адрес2), битовые флаги (4 флага) и счетчик исполнения команды по модулю 4, наращивающийся при каждом выполнении команды. Когда происходит первое выполнение, команды перехода записываются в свободную строку буфера (все поля нулевые) Адрес1, Адрес2 и один флаг, номер которого соответствует счетчику исполнения команд, устанавливается в 1, если переход был. Далее, если соответствующий флаг равен 1, то имеется наличие перехода, если флаг равен 0, то отсутствие перехода. При варианте, что предсказание о переходе оказалось ошибочным, соответствующий флаг инвертируется. Данный алгоритм сокращает количество ошибок при периодическом характере наличия и отсутствия ошибок. К ошибкам приводят все нарушения периода, в том числе и при вычислении периода.
Рассмотренные выше алгоритмы предсказания все время усовершенствуются для минимизации потерь, но свести на данный момент их к нулю не могут. По этой причине рекомендуется уменьшать число команд перехода в программе, причем чем мощнее, а следовательно, с более длинным конвейером используется процессор, тем более требуется.
Параллелизм на уровне команд. Суперскалярность
Все команды программы делятся на независимые и зависимые команды.
Команды называются зависимыми, если их операнды определяются предшествующими командами. Независимыми командами называют те, которые используют константы, введенные данные или данные, для которых команды уже гарантированно выполнены. Команды, готовые для выполнения – это независимые команды. Их можно выполнять одновременно, если имеются свободные устройства для выполнения этих команд.
Суперскалярные процессоры используются для истинного распараллеливания вычислений. Которые имеют не одно, а несколько однотипных устройств для выполнения операций.
CDC 6600 (1964) [5] был первым компьютером, который имел несколько функциональных блоков. Данный компьютер выпустила фирма Control Data Corporation (CDC) при участии одного из ее основателей Суймура Р.Крэя (Seymour R. Cray)
Компьютер CDC 7600 (1969) включал в себя 8 независимых конвейерных устройств, поэтому в нем соединились преимущества конвейерных и суперскалярных ЭВМ.
ILLIAC IV (1974): матричные процессоры. Проект включал в себя сделать 256 процессорных элементов (ПЭ) и разбить их на 4 квадранта по 64 ПЭ, и предусмотреть возможность перестройки в 2 квадранта по 128 ПЭ или 1 квадрант из 256 ПЭ, ткт 40 нс, производительность 1 Гфлоп. Начались работы в 1967 году, к концу 1971 изготовлена система из 1-го квадранта, в 1974 г. она введена в эксплуатацию, доводка велась до 1975 года. Из-за того, что стоимость проекта была в 4 раза выше, сделан лишь 1 квадрант, такт 80нс, реальная производительность до 50 Мфлоп. Но даже при неудачном завершение проекта, данная разработка использовалась при построении серии других суперкомпьютеров.
CRAI 1 (1976): векторно-конвейерные процессоры, создателем которых является компания Cray Research. Время такта 12.5 нс, 12 ковейерных функциональных устройств, пиковая производительность 160 миллионов операций в секунду, оперативная память до 1 Мслова (слово – 64 разряда), цикл памяти 50нс. Самым главным нововведением является включение векторных команд, работающих с целыми массивами независимых данных, которые позволяют эффективно использовать конвейерные функциональные устройства.
Самые первые суперскалярные процессоры фирмы Intel включали в себя два параллельных блока для выполнения операций, первый блок для выполнения произвольных операций, второй – для выполнения только простых операций. Одновременное использование обоих блоков в этом случае было осуществимо только при «правильной» последовательности команд в программе, что при решении конкретных задач практически невозможно. Именно поэтому по возможности компиляторы упорядочивали команды программы таким образом, чтобы максимально использовать оба блока. Тогда и появился режим оптимизации программ, который зависит от используемого процессора.
На сегодняшний момент процессоры суперскалярные и содержат разное число специализированых блоков, к примеру, блоки для выполнения арифметических операций, операций с плавающей точкой.
Параллелизм на уровне данных. SIMD команды
Очень часто, при решении практических задач приходится для множества данных выполнять одну и ту же операцию. В данном случае можно использовать суперскалярность процессоров, но именно для этого случая современные процессоры имеют специальные команды. В соответствии с их назначением они относятся к группе Single Instruction Multiple Data – одна команда для множества данных (SIMD). Векторно-конвейерными называются компьютеры, которые вместе с конвейером обеспечивают возможность одновременной обработки сразу целого массива. Обычно SIMD команды реализуются с помощью специального конвейера, из-за этого могут выполняться одновременно с основным потоком команд. Представителем данного направления является семейство векторно-конвейерных компьютеров CRAY. Для персональных компьютеров ограничен размер блока 128 битами. Блок может интерпретироваться как массив байтов, 2-байтовых и 4-байтовых слов, а также двух данных длинной 8 байтов, и, наконец, одного блока длинной 16 байтов. Набор команд, а также интерпретация данных (целые, с плавающей точкой) все время расширяется. На сегодня для персональных компьютеров используется несколько классов команд этой группы (MMX – Multi Media Extensions., 3DNow, SSE – Streaming SIMD Extension) разных версий. SIMD команды позволяют распараллелить обработку множества данных без накладных расходов. На сегодняшний момент применение этих команд упрощено в связи с возможностью их использования в С программе.
Пример применения операции сложения для массивов целых чисел, состоящих из четырех чисел:
Для сложения чисел фактически выполняется следующие команды:
- загрузка первого массива в 128-битный регистр (т.е. сразу 4-х слагаемых);
- загрузка второго массива в 128-битный регистр (т.е. сразу 4-х слагаемых);
- сложение всех элементов массива (одна команда);
- запись результата в массив.
Параллелизм на уровне задач
Понятие «задача» имеет разный смысл. Если рассматривать процессоров, задачей является программа во время выполнения, а переключение между задачами, это переключение между этими программами, которое инициируется операционной системой и может быть: при истечении кванта времени, если задача ждет выполнения запроса, если требуется выполнения более привилегированных задач. Рассматривая операционные системы, вместо термина задача можно использовать термин процесс, в который фактически вкладывается тот же смысл. Именно поэтому параллелизм на уровне задач предполагает возможность параллельного выполнения отдельных программ. Также наряду с обычными процессами, которым соответствует программа, операционные системы для параллельного выполнения могут использовать отдельных функции процесса (потоки). Рассмотрим параллелизм на уровне процессов и потоков. В этом случае при использовании одного одноядерного процессора может выполняться одновременно только одна функция одного процесса. При режиме разделения времени и высокой скорости выполнения команд может показаться одновременное выполнение, но это не так. Фактически при переключении между потоками старый поток блокируется.
В системах с одни ядром и без Hyper-Threading (HT) технологии в исполнении команд участвует исполнительный блок и внутренний Кеш. Эти элементы вычислительной системы можно назвать вычислительным блоком. Для многопроцессорных систем, вычислительная система имеет несколько вычислительных блоков. Для систем с НТ технологией фактически входит один исполнительный блок, который имеет вид двух логических блоков за счет того, что дублируются некоторые его части (регистры). В многоядерной системе используется несколько вычислительных систем, расположенных физически внутри одной схемы. Многоядерные системы могут использовать как общий внутренний Кеш, так и каждое ядро свой Кеш. Возможна комбинация многоядерности и НТ.
В НТ технологии все ресурсы вычислительного блока (одного) делятся между исполняемыми потоками операционной системой. К примеру, если один поток ждет ввода – вывода данных, то второй поток выполняется с помощью вычислительного блока. Все логические блоки имеют свою копию регистров, поэтому переключения состояния фактически не потребуется, как это в обычных однопроцессорных системах. Общий эффект существенно зависит от потоков, которые работают в паре. При том что все потоки используют одни и те же ресурсы, эффекта фактически не будет, так как устройство одно.
Чтобы достичь истинно параллельного выполнения функций следует иметь несколько процессоров или несколько ядер процессора.
Появление многоядерных процессоров фактически сделало доступными высокопроизводительные вычисления (High Performance Computing – HPC) на домашних компьютерах.
То есть в одной микросхеме располагаются теперь несколько полноценных и равноправных процессорных устройств. Данная технология применяется как в недорогих процессорах (Intel Core 2, AMD Athlon), так и в процессорах для мощных рабочих станций и серверов (AMD Opteron, Intel Xeon). Количество ядер все время растет. На сегодняшний день используются процессоры с 2, 4 и 8 ядрами, в стадии исследования и разработки находятся процессоры с десятками и сотнями ядер, поэтому распараллеливание и масштабирование (т.е. распределение между всеми ядрами процессора) приложений является сложной как теоретической, так и практической задачей, которая на данный момент пока не решена в полной мере.
Память и параллелизм
Как известно, выполнение команд происходит гораздо значительно быстрее, чем доступ к памяти. Чтобы уменьшить потери, связанные с разной скоростью доступа, используется многоуровневая память. Существуют несколько уровней памяти, которые задаются в порядке увеличения времени доступа: регистры, Кеш-память (несколько уровней), оперативная память, внешняя память. Обеспечение параллелизма осуществляется за счет того, что во время выполнения команд и обработки данных используется регистровая и Кеш-память первого уровня, заполняющиеся данными до того, пока они будут использоваться, и до момента, когда они будут нужны, они, как правило, уже находятся в нужной памяти (если конечно, число команд перехода минимизировано!)
Следует рассмотреть классические архитектуры систем с параллельной обработкой данных и команд с точки зрения использования памяти.
Массивно-параллельные компьютеры (MPP)
Данная система включает в себя несколько компьютеров со своей локальной памятью соединяются в одну вычислительную систему с помощью коммутационных устройств [6].
Система состоит из однородных вычислительных узлов, включающих:
- один или несколько центральных процессоров (обычно RISC);
- локальную память (прямой доступ к памяти других узлов невозможен);
- коммуникационный процессор или сетевой адаптер;
- иногда – жесткие диски (как в SP) и/или другие устройства I/O.
Примеры: IBM RS/6000 SP2, Intel PARAGON/ASCI Red, CRAY T3E, Hitachi SR 8000, транспьютерные системы Parsytec.
Достоинством данной архитектуры можно считать возможность ее расширения. Недостаток является медленная передача данных между компьютерами. На сегодняшний момент коммуникационные устройства уменьшают потери, которые связаны с передачей данных, но в любом случае эта операция значительно медленнее, чем при использовании своей памяти.
Симметричные мультипроцессорные системы (SMP – Symmetrical Multi Processor systems)
Одинаковые процессоры подключаются к общей памяти, при этом скорость обращения к общей памяти для всех процессоров одинакова. Процессоры подключаются к памяти либо с помощью общей шины (базовые 2-4-х процессорные SMP-серверы), либо с помощью crossbar-коммутатора (HP 9000). Аппаратно поддерживается когерентность Кешей (гарантия использования актуального значения, данного независимо от того, в каком Кеше изменено его значение). Хоть и проблема передачи данных между памятью решается автоматически, остается ещё одна, это подключение процессоров к общей памяти. Количество процессоров, которые можно подключить, обычно невелико, около 2-4 устройства. Использование 32-х устройств очень дорого, стоимость такой вычислительной системы сотни тысяч долларов.
В связи с использованием общей памяти необходима синхронизация и блокировка в случае попытки доступа к занятому ресурсу с эксклюзивным доступом.
Примеры: HP 9000 V-class, N-class; SMP-сервер и рабочие станции на базе процессоров Intel(IBM, HP,Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.).
Системы с неоднородным доступом к памяти (NUMA – Non-Uniform Memory Access systems)
Состоит система из однородных базовых модулей (плат), которые имеют в своём составе небольшое число процессоров и блок памяти. Объединены модули с помощью высокоскоростного коммутатора. Обеспечивается поддержка единого адресного пространства, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. Доступ к локальной памяти в несколько раз быстрее, чем к удаленной, а скорость доступа к удаленной памяти будет больше, чем дальше будет удалена память от процессора.
В случае если аппаратно поддерживается когерентность Кешей во всей системе (обычно это так), говорят об архитектуре cc-NUMA (cache-coherent NUMA).
В случае попытки доступа к занятому ресурсу с эксклюзивным доступом, при использование общей памяти, необходима синхронизация и блокировка. Также при разработке алгоритма желательно обеспечить доступ к «своей» памяти везде, где есть возможно.
Примеры: Примеры: HP 9000 V-class в SCA-конфигурациях, SGI Origin2000, Sun HPC 10000, IBM/Sequent NUMA-Q 2000, SNI RM600.
Параллельные векторные системы (PVP)
Главным признаком PVP-систем можно считать наличие специальных векторно-конвейерных процессоров, которые имеют команды однотипной обработки векторов независимых данных, которые эффективно выполняются на конвейерных функциональных устройствах.
В основном, несколько таких процессоров (1-16) работают одновременно над общей памятью (аналогично SMP) в многопроцессорных конфигурациях. Объединение несколько узлов происходит с помощью коммутатора (аналогично MPP).
Примеры: NEC SX-4/SX-5, линия векторно-конвейерных компьютеров CRAY: от CRAY-1, CRAY J90/T90, CRAY SV1, CRAY X1, серия Fujitsu VPP.
Кластерные системы
В качестве дешевого варианта массивно-параллельного компьютера используется набор рабочих станций (или даже ПК) общего назначения. Что узлы имели связь используется одна из стандартных сетевых технологий (Fast/Gigabit Ethernet, Myrinet) на базе шинной архитектуры или коммутатора.
Когда происходит объединении в кластер компьютеров разной мощности или разной архитектуры говорят о гетерогенных (неоднородных) кластерах.
Узлы кластера можно одновременно использовать в качестве пользовательских рабочих станций. Если это не нужно, узлы можно существенно облегчить и/или установить в стойку.
Актуальной проблемой является доступа к «чужой» памяти, из-за этого часто такая система используется для одновременного решения нескольких независимых задач.
Примеры: NT-кластер в NCSA, Beowulf-кластеры.
Многоядерные процессоры
С точки зрения программиста, многоядерным процессором является несколько процессоров, имеющие раздельный Кеш 0 уровня (Кеш 2-го и более высоких уровней чаще общий, но может быть и раздельным) и общую оперативную память. По этой причине желательно при разработке алгоритмов обеспечивать максимальную независимость данных, которые используются в разных ядрах. Синхронизация и блокировка являются на данный момент актуальной проблемой.
Используемая литература:
- Flynn M. Very high-speed computing system // Proc. IEEE. 1966. N 54. P.1901-1909.
- Hwang K., Briggs F.A. Computer Architecture and Parallel Processing. 1984. P.32-40.
- http://ru.wikipedia.org/wiki/Параллельные_вычисления; http://ru.wikipedia.org/wiki/Нейрокомпьютер ;
- Гергелъ В.П., Стронгин Р.Г Основы параллельных вычислений для многопроцессорных вычислительных систем. Нижний Новгород: -Издательство Нижегородского госуниверситета, 2003
- Воеводин В.В., Воеводин Вл.в. Параллельные вычисления. СПб: БХВ – Петербург, 2004 – 608с.